반응형

이번엔 딥러닝 실습으로 0부터 9까지의 숫자를 쓴 손글씨 이미지 데이터를 분석하여 숫자를 분류하는 실습입니다.
모델 설계 및 모델학습방법 설정
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 모델 설계
model = Sequential()
# 딥러닝 기초 토대
input_data_shape = 5 # 첫번째 층(입력층)에서 사용
output_data = 1 # 마지막 층(출력층)에서 사용
# 층 설계
model.add(Dense(10, input_dim=input_data_shape, activation='relu'))
model.add(Dense(20, activation='relu'))
model.add(Dense(30, activation='relu'))
model.add(Dense(20, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(output_data , activation='sigmoid'))
# 모델 학습 방법 설정
model.compile(
loss = 'binary_crossentropy',
optimizer = 'adam',
metrics = ['accuracy'] # 회귀에서는 생략
)
훈련데이터, 테스트데이터 분류
from tensorflow.keras.datasets import mnist
# 튜플형태 데이터
((X_train, y_train), (X_test, y_test)) = mnist.load_data()
X_train.shape, y_train.shape, X_test.shape, y_test.shape
훈련데이터 확인
손글씨 데이터는 가로와 세로가 28픽셀씩 총 784픽셀로 이루어진 이미지 형태이며 0~255사이의 값으로 0은 흰색, 중간값은 회색, 255는 검정색을 의미한다.
import matplotlib.pyplot as plt
plt.imshow(X_train[4], cmap=plt.cm.binary)
plt.show()
# 28 x 28 = 784픽셀
# 0~255 = 흰색 ~ 회색 ~ 검정색
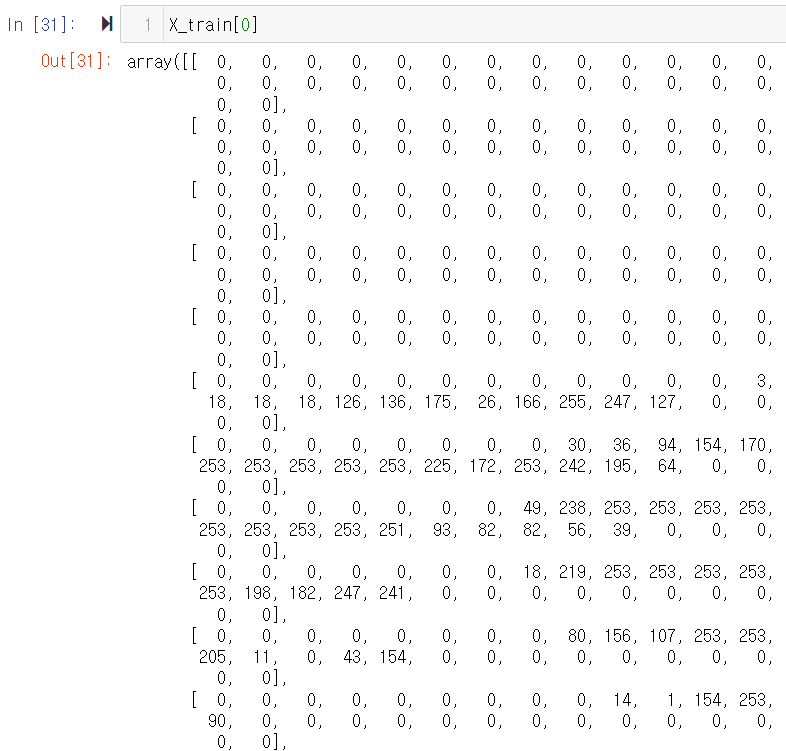
훈련데이터의 0번째 데이터의 array 리스트 형태의 값을 보면 공백부분(흰색)은 0으로 채워져 있고 손글씨 부분은 255까지의 숫자로 채워진걸 확인할 수 있습니다.
데이터 전처리
# 정답데이터의 데이터 중복제거값 확인
import numpy as np
np.unique(y_train)
# mlp는 1차원의 데이터만 학습 가능
# 28 x 28인 2차원 데이터를 학습시키기위해 784의 1차원 데이터로 변경
# 필수사항
X_train = X_train.reshape((60000,784))
X_test = X_test.reshape((10000,784))
# 데이터가 0 ~ 255 사이의 숫자로 구성
# 범위가 큰 값을 사용하게 되면 계산중 오차가 커짐
# 데이터의 범위를 0~1까지로 변경
# 권장사항
X_train = X_train.astype('float32')/255
X_test = X_test.astype('float32')/255
# 정답 데이터 원핫 인코딩
import pandas as pd
y_train = pd.get_dummies(y_train)
y_test = pd.get_dummies(y_test)
모델 및 층설계, 모델학습 방법 설정
# 입력층 입력데이터 크기 : 784
# 출력층에서 출력해야하는 데이터의 크기 : 10
# 모델 설계
model = Sequential()
# 층 설계
model.add(Dense(10, input_dim=784, activation='relu'))
model.add(Dense(20, activation='relu'))
model.add(Dense(30, activation='relu'))
model.add(Dense(20, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(10 , activation='softmax'))
# 모델 학습 방법 설정
model.compile(
loss = 'categorical_crossentropy',
optimizer = 'adam',
metrics = ['accuracy'] # 회귀에서는 생략
)
model.fit(X_train, y_train, epochs=20)
# 출력 #
Train on 60000 samples
Epoch 1/20
60000/60000 [==============================] - 4s 68us/sample - loss: 0.6798 - accuracy: 0.7810
Epoch 2/20
60000/60000 [==============================] - 4s 60us/sample - loss: 0.3104 - accuracy: 0.9097
Epoch 3/20
60000/60000 [==============================] - 4s 60us/sample - loss: 0.2527 - accuracy: 0.9263
Epoch 4/20
60000/60000 [==============================] - 4s 60us/sample - loss: 0.2270 - accuracy: 0.9328
Epoch 5/20
60000/60000 [==============================] - 4s 60us/sample - loss: 0.2080 - accuracy: 0.9388
Epoch 6/20
60000/60000 [==============================] - 4s 60us/sample - loss: 0.1952 - accuracy: 0.9421
Epoch 7/20
60000/60000 [==============================] - 4s 60us/sample - loss: 0.1848 - accuracy: 0.9456
Epoch 8/20
60000/60000 [==============================] - 3s 58us/sample - loss: 0.1765 - accuracy: 0.9468
Epoch 9/20
60000/60000 [==============================] - 3s 58us/sample - loss: 0.1681 - accuracy: 0.9502
Epoch 10/20
60000/60000 [==============================] - 3s 58us/sample - loss: 0.1624 - accuracy: 0.9516
Epoch 11/20
60000/60000 [==============================] - 3s 58us/sample - loss: 0.1583 - accuracy: 0.9514
Epoch 12/20
60000/60000 [==============================] - 3s 58us/sample - loss: 0.1542 - accuracy: 0.9531
Epoch 13/20
60000/60000 [==============================] - 3s 58us/sample - loss: 0.1482 - accuracy: 0.9549
Epoch 14/20
60000/60000 [==============================] - 4s 59us/sample - loss: 0.1464 - accuracy: 0.9557
Epoch 15/20
60000/60000 [==============================] - 4s 60us/sample - loss: 0.1412 - accuracy: 0.9569
Epoch 16/20
60000/60000 [==============================] - 4s 59us/sample - loss: 0.1387 - accuracy: 0.9575
Epoch 17/20
60000/60000 [==============================] - 4s 58us/sample - loss: 0.1366 - accuracy: 0.9582
Epoch 18/20
60000/60000 [==============================] - 3s 58us/sample - loss: 0.1334 - accuracy: 0.9595
Epoch 19/20
60000/60000 [==============================] - 3s 58us/sample - loss: 0.1330 - accuracy: 0.9598
Epoch 20/20
60000/60000 [==============================] - 3s 58us/sample - loss: 0.1288 - accuracy: 0.9607
<tensorflow.python.keras.callbacks.History at 0x2086e367780>
relu --> sigmoid로 변경
모델의 입력층과 중간층의 활성화함수(activation)를 기존 "relu"에서 "sigmoid"로 변경하여 모델을 재설계후 학습을 시켜 relu와 sigmoid의 선능을 비교 해보겠습니다.
# 모든 조건은 동일
# model22라는 딥러닝 모델 설계
# 입력층과 중간층의 활성화함수 sigmoid > sigmoid
# 모델 설계후 학습시켜보기
# 입력층 입력데이터 크기 : 784
# 출력층에서 출력해야하는 데이터의 크기 : 10
# 모델 설계
model2 = Sequential()
# 층 설계
model2.add(Dense(10, input_dim=784, activation='sigmoid'))
model2.add(Dense(20, activation='sigmoid'))
model2.add(Dense(30, activation='sigmoid'))
model2.add(Dense(20, activation='sigmoid'))
model2.add(Dense(10, activation='sigmoid'))
model2.add(Dense(10 , activation='softmax'))
# 모델 학습 방법 설정
model2.compile(
loss = 'categorical_crossentropy',
optimizer = 'adam',
metrics = ['accuracy'] # 회귀에서는 생략
)
model2.fit(X_train, y_train, epochs=20)
# 출력 #
Train on 60000 samples
Epoch 1/20
60000/60000 [==============================] - 4s 65us/sample - loss: 1.9202 - accuracy: 0.2307
Epoch 2/20
60000/60000 [==============================] - 3s 57us/sample - loss: 1.4321 - accuracy: 0.4365
Epoch 3/20
60000/60000 [==============================] - 3s 57us/sample - loss: 1.1882 - accuracy: 0.5268
Epoch 4/20
60000/60000 [==============================] - 3s 57us/sample - loss: 1.0511 - accuracy: 0.5964
Epoch 5/20
60000/60000 [==============================] - 3s 57us/sample - loss: 0.9653 - accuracy: 0.6321
Epoch 6/20
60000/60000 [==============================] - 3s 58us/sample - loss: 0.9156 - accuracy: 0.6489
Epoch 7/20
60000/60000 [==============================] - 3s 57us/sample - loss: 0.8795 - accuracy: 0.6680
Epoch 8/20
60000/60000 [==============================] - 3s 58us/sample - loss: 0.8410 - accuracy: 0.6940
Epoch 9/20
60000/60000 [==============================] - 3s 58us/sample - loss: 0.8039 - accuracy: 0.7167
Epoch 10/20
60000/60000 [==============================] - 4s 59us/sample - loss: 0.7653 - accuracy: 0.7370
Epoch 11/20
60000/60000 [==============================] - 4s 59us/sample - loss: 0.7201 - accuracy: 0.7570
Epoch 12/20
60000/60000 [==============================] - 3s 58us/sample - loss: 0.6787 - accuracy: 0.7721
Epoch 13/20
60000/60000 [==============================] - 3s 58us/sample - loss: 0.6490 - accuracy: 0.7829
Epoch 14/20
60000/60000 [==============================] - 3s 58us/sample - loss: 0.6195 - accuracy: 0.8073
Epoch 15/20
60000/60000 [==============================] - 3s 58us/sample - loss: 0.5603 - accuracy: 0.8552
Epoch 16/20
60000/60000 [==============================] - 4s 59us/sample - loss: 0.5205 - accuracy: 0.8706
Epoch 17/20
60000/60000 [==============================] - 3s 58us/sample - loss: 0.4924 - accuracy: 0.8795
Epoch 18/20
60000/60000 [==============================] - 3s 58us/sample - loss: 0.4719 - accuracy: 0.8853
Epoch 19/20
60000/60000 [==============================] - 4s 59us/sample - loss: 0.4560 - accuracy: 0.8887
Epoch 20/20
60000/60000 [==============================] - 3s 58us/sample - loss: 0.4397 - accuracy: 0.8927
<tensorflow.python.keras.callbacks.History at 0x2086e7b6710>
성능 개선되지 않으면 모델학습 중단시키기
모델을 성능 개선을 위해 많은 횟수의 학습을 하는데 모델의 성능 개선이 없음에도 epoch의 설정값 만큼 학습을 진행한다면 시간과 리소스 낭비를 하게 된다. 성능개선 없는 학습을 차단하기 위해 Modelcheckpoin, Earlystopping 라이브러리를 사용하여 최적의 모델을 찾아 저장하고 모델 학습을 중단시켜 보겠습니다.
# 모델의 학습 중단이 필요한 이유
# 1. 마지막 epoch가 반드시 가장 좋은 모델은 아님
# 2. epoch가 많아지면 마지막 부분의 epoch는 모델의 성능이 향상되지 않아 시간낭비
# 베스트 모델 찾아서 저장하고, 모델 학습 중단하기
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
# 저장할 파일명 설정
# {epoch:04d} : 반복수를 4자리 정수로 표현
# {accuracy:.4f} : 정확도를 소수점 4자리까지 표현
modelpath = './model/model-{epoch:04d}-{accuracy:.4f}.h5'
# 성능이 개선된 모델을 찾아서 저장
# ModelCheckpoint(저장경로, 기준값, save_best_only=True, vervose=1)
mc = ModelCheckpoint(filepath = modelpath,
monitor = 'accuracy',
save_best_only = True,
verbose=1)
# 성능이 개선되지 않는다면 학습을 중단
# EaryStopping(기준값, 기다리는 횟수)
es = EarlyStopping(monitor='accuracy',
patience=20)
model.fit(X_train,y_train,epochs=1000, callbacks=[mc,es])
# 출력 #
Epoch 281/1000
59872/60000 [============================>.] - ETA: 0s - loss: 0.0498 - accuracy: 0.9836
Epoch 00281: accuracy did not improve from 0.98530
60000/60000 [==============================] - 4s 61us/sample - loss: 0.0498 - accuracy: 0.9836
Epoch 282/1000
59296/60000 [============================>.] - ETA: 0s - loss: 0.0480 - accuracy: 0.9849
Epoch 00282: accuracy did not improve from 0.98530
60000/60000 [==============================] - 4s 61us/sample - loss: 0.0478 - accuracy: 0.9850
Epoch 283/1000
59488/60000 [============================>.] - ETA: 0s - loss: 0.0453 - accuracy: 0.9850
Epoch 00283: accuracy did not improve from 0.98530
60000/60000 [==============================] - 4s 59us/sample - loss: 0.0453 - accuracy: 0.9850
Epoch 284/1000
59552/60000 [============================>.] - ETA: 0s - loss: 0.0454 - accuracy: 0.9848
Epoch 00284: accuracy did not improve from 0.98530
60000/60000 [==============================] - 4s 59us/sample - loss: 0.0455 - accuracy: 0.9848
Epoch 285/1000
59968/60000 [============================>.] - ETA: 0s - loss: 0.0481 - accuracy: 0.9844
Epoch 00285: accuracy did not improve from 0.98530
60000/60000 [==============================] - 4s 59us/sample - loss: 0.0481 - accuracy: 0.9844
Epoch 286/1000
59808/60000 [============================>.] - ETA: 0s - loss: 0.0481 - accuracy: 0.9846
Epoch 00286: accuracy did not improve from 0.98530
60000/60000 [==============================] - 4s 59us/sample - loss: 0.0482 - accuracy: 0.9846
Epoch 287/1000
59360/60000 [============================>.] - ETA: 0s - loss: 0.0468 - accuracy: 0.9841
Epoch 00287: accuracy did not improve from 0.98530
60000/60000 [==============================] - 4s 59us/sample - loss: 0.0469 - accuracy: 0.9840
Epoch 288/1000
59360/60000 [============================>.] - ETA: 0s - loss: 0.0472 - accuracy: 0.9849
Epoch 00288: accuracy did not improve from 0.98530
60000/60000 [==============================] - 4s 59us/sample - loss: 0.0469 - accuracy: 0.9850
Epoch 289/1000
59584/60000 [============================>.] - ETA: 0s - loss: 0.0452 - accuracy: 0.9852
Epoch 00289: accuracy did not improve from 0.98530
60000/60000 [==============================] - 4s 59us/sample - loss: 0.0452 - accuracy: 0.9852
Epoch 290/1000
59776/60000 [============================>.] - ETA: 0s - loss: 0.0463 - accuracy: 0.9843
Epoch 00290: accuracy did not improve from 0.98530
60000/60000 [==============================] - 4s 59us/sample - loss: 0.0463 - accuracy: 0.9843
Epoch 291/1000
59520/60000 [============================>.] - ETA: 0s - loss: 0.0483 - accuracy: 0.9844
Epoch 00291: accuracy did not improve from 0.98530
60000/60000 [==============================] - 4s 59us/sample - loss: 0.0484 - accuracy: 0.9844
<tensorflow.python.keras.callbacks.History at 0x208787f8cf8>
교차검증 하기
# 모델 검증
# 교차 검증 : k_fold
from sklearn.model_selection import KFold, cross_val_score
# 교차검증시 model부분에 model의설계,설정이 들어가야되서 함수로 만들어야된다.
def deep_model():
# 모델 설계
model = Sequential()
# 층 설계
model.add(Dense(10, input_dim=784, activation='relu'))
model.add(Dense(20, activation='relu'))
model.add(Dense(30, activation='relu'))
model.add(Dense(20, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(10 , activation='softmax'))
# 모델 학습 방법 설정
model.compile(
loss = 'categorical_crossentropy',
optimizer = 'adam',
metrics = ['accuracy'] # 회귀에서는 생략
)
return model
# 학습 방법 설정
from tensorflow.keras.wrappers.scikit_learn import KerasClassifier
deepmodel = KerasClassifier(build_fn = deep_model, epochs = 20)
fold = KFold(n_splits = 5, shuffle = True)
score = cross_val_score(deepmodel, X_train, y_train, cv=fold)
# 출력 #
Epoch 12/20
48000/48000 [==============================] - 3s 58us/sample - loss: 0.1703 - accuracy: 0.9477
Epoch 13/20
48000/48000 [==============================] - 3s 58us/sample - loss: 0.1682 - accuracy: 0.9486
Epoch 14/20
48000/48000 [==============================] - 3s 58us/sample - loss: 0.1637 - accuracy: 0.9499
Epoch 15/20
48000/48000 [==============================] - 3s 59us/sample - loss: 0.1597 - accuracy: 0.9507
Epoch 16/20
48000/48000 [==============================] - 3s 59us/sample - loss: 0.1582 - accuracy: 0.9515
Epoch 17/20
48000/48000 [==============================] - 3s 59us/sample - loss: 0.1520 - accuracy: 0.9521
Epoch 18/20
48000/48000 [==============================] - 3s 59us/sample - loss: 0.1512 - accuracy: 0.9524
Epoch 19/20
48000/48000 [==============================] - 3s 59us/sample - loss: 0.1478 - accuracy: 0.9542
Epoch 20/20
48000/48000 [==============================] - 3s 58us/sample - loss: 0.1462 - accuracy: 0.9546
12000/12000 [==============================] - 1s 50us/sample - loss: 0.2017 - accuracy: 0.9415
모델평가 평균값 확인
score.mean()
# 출력 #
0.9456166625022888
스마트인재개발원 사이트 : https://www.smhrd.or.kr/
스마트인재개발원
4차산업혁명시대를 선도하는 빅데이터, 인공지능, 사물인터넷 전문 '0원' 취업연계교육기관
www.smhrd.or.kr
반응형
'Learn Coding > 스마트인재개발원(인공지능)' 카테고리의 다른 글
| 딥러닝(Deep learning) 이론 및 실습#2 - 스마트인재개발원 (0) | 2021.12.20 |
|---|---|
| 딥러닝(Deep learning) 이론 및 실습#1 - 스마트인재개발원 (0) | 2021.12.19 |
| 머신러닝(Machine Learning) 기초 (0) | 2021.11.18 |
| 머신러닝을 위한 기초통계 개념정리 (0) | 2021.11.18 |
| 스마트인재개발원 - 인공지능/빅데이터/IOT교육기관 (0) | 2021.11.16 |




댓글